Sampling Methods
This chapter introduces several fundamental concepts related to sampling methods. In particular, the statistical properties of the Monte Carlo estimator are discussed (Monte Carlo (MC)) and strategies for multilevel and multifidelity sampling are introduced within this context. Hereafter, multilevel refers to the possibility of exploiting distinct discretization levels (i.e. space/time resolution) within a single model form, whereas multifidelity involves the use of more than one model form. In Multifidelity Monte Carlo, we describe the multifidelity Monte Carlo and its single fidelity model version, the control variate Monte Carlo, that we align with multifidelity sampling, and in Multilevel Monte Carlo, we describe the multilevel Monte Carlo algorithm that we align with multilevel sampling. In A multilevel-multifidelity approach, we show that these two approaches can be combined to create multilevel-multifidelity sampling approaches. Finally, this chapter discusses Quasi-Monte Carlo (QMC) or low-discrepancy sampling.
Monte Carlo (MC)
Monte Carlo is a popular algorithm for stochastic simulations due to its simplicity, flexibility, and the provably convergent behavior that is independent of the number of input uncertainties. A quantity of interest \(Q: \Xi \rightarrow \mathbb{R}\), represented as a random variable (RV), can be introduced as a function of a random vector \(\boldsymbol{\xi} \in \Xi \subset \mathbb{R}^d\). The goal of any MC simulation is computing statistics for \(Q\), e.g. the expected value \(\mathbb{E}\left[Q\right]\). The MC estimator \(\hat{Q}_N^{MC}\) for \(\mathbb{E}\left[Q\right]\) is defined as follows
where \(Q^{(i)} = Q(\boldsymbol{\xi}^{(i)})\) and \(N\) is used to indicate the number of realizations of the model.
The MC estimator is unbiased, i.e., its bias is zero and its convergence to the true statistics is \(\mathcal{O}(N^{-1/2})\). Moreover, since each set of realizations for \(Q\) is different, another crucial property of any estimator is its own variance:
Furthermore, it is possible to show, in the limit \(N \rightarrow \infty\), that the error \(\left( \mathbb{E}\left[Q\right] - \hat{Q}_N^{MC} \right) \sim \sqrt{\dfrac{\mathbb{V}ar\left(Q\right) }{N}} \mathcal{N}(0,1)\), where \(\mathcal{N}(0,1)\) represents a standard normal RV. As a consequence, it is possible to define a confidence interval for the MC estimator which has an amplitude proportional to the standard deviation of the estimator. Indeed, the variance of the estimator plays a fundamental role in the quality of the numerical results: the reduction of the estimator variance correspond to an error reduction in the statistics.
Multifidelity Monte Carlo
A closer inspection of Eq. (37) indicates that only an increase in the number of simulations \(N\) might reduce the overall variance, since \(\mathbb{V}ar\left({Q}\right)\) is an intrinsic property of the model under analysis. However, more sophisticated techniques have been proposed to accelerate the convergence of a MC simulation. For instance, an incomplete list of these techniques can include stratified sampling, importance sampling, Latin hypercube, deterministic Sobol’ sequences and control variates (see [Owe13]). In particular, the control variate approach, is based on the idea of replacing the RV \(Q\) with one that has the same expected value, but with a smaller variance. The goal is to reduce the numerator in Eq. (37), and hence the value of the estimator variance without requiring a larger number of simulations. In a practical setting, the control variate makes use of an auxiliary RV \(G=G(\boldsymbol{\xi})\) for which the expected value \(\mathbb{E}\left[G\right]\) is known. Indeed, the alternative estimator can be defined as
The MC control variate estimator \(\hat{Q}_N^{MCCV}\) is unbiased, but its variance now has a more complex dependence not only on the \(\mathbb{V}ar\left({Q}\right)\), but also on \(\mathbb{V}ar\left(G\right)\) and the covariance between \(Q\) and \(G\) since
The parameter \(\beta\) can be used to minimize the overall variance leading to
for which the estimator variance follows as
Therefore, the overall variance of the estimator \(\hat{Q}_N^{MCCV}\) is proportional to the variance of the standard MC estimator \(\hat{Q}_N^{MC}\) through a factor \(1-\rho^2\) where \(\rho = \dfrac{ \mathrm{Cov}\left(Q,G\right) }{\sqrt{\mathbb{V}ar\left(Q\right)\mathbb{V}ar\left(G\right)}}\) is the Pearson correlation coefficient between \(Q\) and \(G\). Since \(0<\rho^2<1\), the variance \(\mathbb{V}ar\left( \hat{Q}_N^{MCCV} \right)\) is always less than the corresponding \(\mathbb{V}ar\left({\hat{Q}_N^{MC}}\right)\). The control variate technique can be seen as a very general approach to accelerate a MC simulation. The main step is to define a convenient control variate function which is cheap to evaluate and well correlated to the target function. For instance, function evaluations obtained through a different (coarse) resolution may be employed or even coming from a more crude physical/engineering approximation of the problem. A viable way of building a well correlated control variate is to rely on a low-fidelity model (i.e. a crude approximation of the model of interest) to estimate the control variate using estimated control means (see [NgW14, PTSW14] for more details). In this latter case, clearly the expected value of the low-fidelity model is not known and needs to be computed.
With a slight change in notation, it is possible to write
\[\hat{Q}^{CVMC} = \hat{Q} + \alpha_1 \left( \hat{Q}_1 - \hat{\mu}_1 \right),\]
where \(\hat{Q}\) represents the MC estimator for the high-fidelity model, \(\hat{Q}_1\) the MC estimator for the low-fidelity model and \(\hat{\mu}_1\) a different approximation for \(\mathbb{E}[Q_1]\). If \(N\) samples are used for approximating \(\hat{Q}\) and \(\hat{Q}_1\) and a total of \(r_1 N\) samples for the low-fidelity models are available, an optimal solution, which guarantees the best use of the low-fidelity resources, can be obtained following [NgW14] as
where \(\mathcal{C}\) and \(\mathcal{C}_1\) represent the cost of evaluating the high- and low-fidelity models, respectively and \(\rho_1\) is the correlation between the two models. This solution leads to the following expression for the estimator variance
which shows similarities with the variance of a control variate estimator with the only difference being the term \(\frac{r_1-1}{r_1}\) that, by multiplying the correlation \(\rho_1\), effectively penalizes the estimator due to the need for estimating the low-fidelity mean.
Another common case encountered in practice is the availability of more than a low-fidelity model. In this case, the multifidelity Monte Carlo can be extended following [PWG16, PWG18] as
where \(\hat{Q}_i\) represents the generic ith low-fidelity model.
The MFMC estimator is still unbiased (similarly to MC) and share similarities with CVMC; indeed one can recover CVMC directly from it. For each low-fidelity model we use \(N_i r_i\) samples, as in the CVMC case, however for \(i \geq 2\), the term \(\hat{Q_i}\) is approximated with exactly the same samples of the previous model, while each \(\hat{\mu}_i\) is obtained by adding to this set a number of \((r_i-r_{i-1}) N_i\) additional independent samples. Following [PWG16] the weights can be obtained as
The optimal resource allocation problem is also obtainable in closed-form if, as demonstrated in [PWG16] the following conditions, for the models’ correlations and costs, hold
leading to
Multilevel Monte Carlo
In general engineering applications, the quantity of interest \(Q\) is obtained as the result of the numerical solution of a partial partial differential equation (possibly a system of them). Therefore, the dependence on the physical \(\mathbf{x} \in \Omega\subset\mathbb{R}^n\) and/or temporal \(t \in T\subset\mathbb{R^+}\) coordinates should be included, hence \(Q=Q(\mathbf{x}, \boldsymbol{\xi}, t)\). A finite spatial/temporal resolution is always employed to numerically solve a PDE, implying the presence of a discretization error in addition to the stochastic error. The term discretization is applied generically with reference to either the spatial tessellation, the temporal resolution, or both (commonly, they are linked). For a generic tessellation with \(M\) degrees-of-freedom (DOFs), the PDE solution of \(Q\) is referred to as \(Q_M\). Since \(Q_M \rightarrow Q\) for \(M\rightarrow\infty\), then \(\mathbb{E}\left[{Q_M}\right] \rightarrow \mathbb{E}\left[{Q}\right]\) for \(M\rightarrow\infty\) with a prescribed order of convergence. A MC estimator in presence of a finite spatial resolution and finite sampling is
for which the mean square error (MSE) is
where the first term represents the variance of the estimator, and the second term \(\left( \mathbb{E}\left[ Q_M-Q \right] \right)^2\) reflects the bias introduced by the (finite) spatial discretization. The two contributions appear to be independent of each other; accurate MC estimates can only be obtained by drawing the required \(N\) number of simulations of \(Q_M( \boldsymbol{\xi} )\) at a sufficiently fine resolution \(M\). Since the numerical cost of a PDE is related to the number of DOFs of the tessellation, the total cost of a MC simulation for a PDE can easily become intractable for complex multi-physics applications that are computationally intensive.
Multilevel Monte Carlo for the mean
The multilevel Monte Carlo (MLMC) algorithm has been introduced, starting from the control variate idea, for situation in which additional discretization levels can be defined. The basic idea, borrowed from the multigrid approach, is to replace the evaluation of the statistics of \(Q_M\) with a sequence of evaluations at coarser levels. If it is possible to define a sequence of discretization levels \(\left\{ M_\ell: \ell = 0, \dots, L \right\}\) with \(M_0 < M_1 < \dots < M_L \stackrel{\mathrm{def}}{=} M\), the expected value \(\mathbb{E}\left[{Q_M}\right]\) can be decomposed, exploiting the linearity of the expected value operator as
If the difference function \(Y_\ell\) is defined according to
the expected value \(\mathbb{E}\left[{Q_M}\right]=\sum_{\ell=0}^{L}{ \mathbb{E}\left[Y_\ell\right] }\). A multilevel MC estimator is obtained when a MC estimator is adopted independently for the evaluation of the expected value of \(Y_\ell\) on each level. The resulting multilevel estimator \(\hat{Q}_M^{\mathrm{ML}}\) is
Since the multilevel estimator is unbiased, the advantage of using this formulation is in its reduced estimator variance \(\sum_{\ell=0}^{L} N_\ell^{-1} \mathbb{V}ar\left({Y_\ell}\right)\): since \(Q_M \rightarrow Q\), the difference function \(Y_\ell \rightarrow 0\) as the level \(\ell\) increases. Indeed, the corresponding number of samples \(N_\ell\) required to resolve the variance associated with the \(\ell\)th level is expected to decrease with \(\ell\).
The MLMC algorithm can be interpreted as a strategy to optimally allocate resources. If the total cost of the MLMC algorithm is written as
with \(\mathcal{C}_{\ell}\) being the cost of the evaluation of \(Y_\ell\) (involving either one or two discretization evaluations), then the following constrained minimization problem can be formulated where an equality constraint enforces a stochastic error (from MLMC estimator variance) equal to the residual bias error (\(\varepsilon^2/2\))
using a Lagrange multiplier \(\lambda\). This equality constraint reflects a balance between the two contributions to MSE, reflecting the goal to not over-resolve one or the other. The result of the minimization is
defining an optimal sample allocation per discretization level.
MLMC extension to the variance
Despite the original introduction of the MLMC approach for the computation of the mean estimator in [Gil08, Gil15], it is possible to estimate higher-order moments with a MLMC sampling strategy, as for instance the variance.
A single level unbiased estimator for the variance of a generic QoI at the highest level \(M_L\) of the hierarchy can be written as
The multilevel version of Eq. (41) can be obtained via a telescopic expansion in term of difference of estimators over subsequent levels. To simplify the notation and for simplicity of exposure from now on we only indicate the level, i.e. \(M_\ell = \ell\).
The expansion is obtained by re-writing Eq. (41) as
It is important here to note that since the estimators at the levels \(\ell\) and \(\ell-1\) are computed with the same number of samples both estimators use the factor \(1/(N_\ell-1)\) to obtain their unbiased version. Moreover, each estimator is indeed written with respect to its own mean value, i.e. the mean value on its level, either \(\ell\) or \(\ell-1\). This last requirement leads to the computation of a local expected value estimator with respect to the same samples employed for the difference estimator. If we now denote with \(\hat{Q}_{\ell,2}\) the sampling estimator for the second order moment of the QoI \(Q_\ell\) we can write
where
Note that \(\hat{Q}_{\ell,2}\) and \(\hat{Q}_{\ell - 1,2}\) are explicitly sharing the same samples \(N_\ell\).
For this estimator we are interested in minimizing its cost while also prescribing its variance as done for the expected value. This is accomplished by evaluating the variance of the multilevel variance estimator \(\hat{Q}_{L,2}^{ML}\)
where the covariance term is a result of the dependence described in (43).
The previous expression can be evaluated once the variance for the sample estimator of the second order order moment \(\mathbb{V}ar\left[ \hat{Q}_{\ell,2} \right]\) and the covariance term \(\mathbb{C}ov\left( \hat{Q}_{\ell,2},\hat{Q}_{\ell-1,2} \right)\) are known. These terms can be evaluated as:
where \(\hat{Q}_{\ell,4}\) denotes the sampling estimator for the fourth order central moment.
The expression for the covariance term is more involved and can be written as
The first term of the previous expression is evaluated by estimating and combining several sampling moments as
It is important to note here that the previous expression can be computed only if several sampling estimators for product of the QoIs at levels \(\ell\) and \(\ell-1\) are available. These quantities are not required in the standard MLMC implementation for the mean and therefore for the estimation of the variance more data need to be stored to assemble the quantities on each level.
An optimization problem, similar to the one formulated for the mean in the previous section, can be written in the case of variance
This optimization problem can be solved in two different ways, namely an analytical approximation and by solving a non-linear optimization problem. The analytical approximation follows the approach described in [PKN17] and introduces a helper variable
Next, the following constrained minimization problem is formulated
and a closed form solution is obtained
similarly as for the expected value in (40).
The second approach uses numerical optimization directly on the non-linear optimization problem (44) to find an optimal sample allocation. Dakota uses OPTPP as the default optimizer and switches to NPSOL if it is available.
Both approaches for finding the optimal sample allocation when allocating for the variance are currently implemented in Dakota. The analytical solution is employed by default while the optimization is enabled using a keyword. We refer to the reference manual for a discussion of the keywords to select these different options.
MLMC extension to the standard deviation
The extension of MLMC for the standard deviation is slightly more complicated by the presence of the square root, which prevents a straightforward expansion over levels.
One possible way of obtaining a biased estimator for the standard deviation is
To estimate the variance of the standard deviation estimator, it is possible to leverage the result, derived in the previous section for the variance, and write the variance of the standard deviation as a function of the variance and its estimator variance. If we can estimate the variance \(\hat{Q}_{L,2}\) and its estimator variance \(\mathbb{V}ar\left[ \hat{Q}_{L,2} \right]\), the variance for the standard deviation \(\hat{\sigma}_L^{ML}\) can be approximated as
Similarly to the variance case, a numerical optimization problem can be solved to obtain the sample allocation for the estimator of the standard deviation given a prescribed accuracy target.
MLMC extension to the scalarization function
Often, especially in the context of optimization, it is necessary to estimate statistics of a metric defined as a linear combination of mean and standard deviation of a QoI. A classical reliability measure \(c^{ML}[Q]\) can be defined, for the quantity \(Q\), starting from multilevel (ML) statistics, as
To obtain the sample allocation, in the MLMC context, it is necessary to evaluate the variance of \(c_L^{ML}[Q]\), which can be written as
This expression requires, in addition to the already available terms \(\mathbb{V}ar\left[ \hat{Q}_{L}^{ML} \right]\) and \(\mathbb{V}ar\left[ \hat{\sigma}_L^{ML} \right]\), also the covariance term \(\mathbb{C}ov\left[ \hat{Q}_{L}^{ML}, \hat{\sigma}_L^{ML} \right]\). This latter term can be written knowing that shared samples are only present on the same level
which leads to the need for evaluating the following four contributions
In Dakota, we adopt the following approximation, for two arbitrary levels \(\ell\) and \(\kappa \in \left\{ \ell-1, \ell, \ell+1 \right\}\)
(we indicate with \(\hat{Q}_{\kappa,2}\) the second central moment for \(Q\) at the level \(\kappa\)), which corresponds to assuming that the correlation between expected value and variance is a good approximation of the correlation between the expected value and the standard deviation. This assumption is particularly convenient because it is possible to obtain in closed form the covariance between expected value and variance and, therefore, we can adopt the following approximation
Finally, we can derive the term \(\mathbb{C}ov\left[ \hat{Q}_{\ell}, \hat{Q}_{\kappa,2} \right]\) for all possible cases
Even for this case, the sample allocation problem can be solved by resorting to a numerical optimization given a prescribed target.
A multilevel-multifidelity approach
The MLMC approach described in Multilevel Monte Carlo can be related to a recursive control variate technique in that it seeks to reduce the variance of the target function in order to limit the sampling at high resolution. In addition, the difference function \(Y_\ell\) for each level can itself be the target of an additional control variate (refer to Multifidelity Monte Carlo). A practical scenario is when not only different resolution levels are available (multilevel part), but also a cheaper computational model can be used (multifidelity part). The combined approach is a multilevel-multifidelity algorithm [FDKI17, GIE15, NT15], and in particular, a multilevel-control variate Monte Carlo sampling approach.
\(Y_l\) correlations
If the target QoI can be generated from both a high-fidelity (HF) model and a cheaper, possibly biased low-fidelity (LF) model, it is possible to write the following estimator
where
The estimator \(Y^{\mathrm{HF},\star}_{\ell}\) is unbiased with respect to \(\hat{Y}^{\mathrm{HF}}_{\ell}\), hence with respect to the true value \(\mathbb{E}\left[Y^{\mathrm{HF}}_{\ell}\right]\). The control variate is obtained by means of the LF model realizations for which the expected value can be computed in two different ways: \(\hat{Y}^{\mathrm{LF}}_{\ell}\) and \(\mathbb{E}\left[Y^{\mathrm{LF}}_{\ell}\right]\). A MC estimator is employed for each term but the estimation of \(\mathbb{E}\left[Y^{\mathrm{LF}}_{\ell}\right]\) is more resolved than \(\hat{Y}^{\mathrm{LF}}_{\ell}\). For \(\hat{Y}^{\mathrm{LF}}_{\ell}\), we choose the number of LF realizations to be equal to the number of HF realizations, \(N_{\ell}^{\mathrm{HF}}\). For the more resolved \(\mathbb{E}\left[Y^{\mathrm{LF}}_{\ell}\right]\), we augment with an additional and independent set of realizations \(\Delta_{\ell}^{\mathrm{LF}}\), hence \(N_{\ell}^{\mathrm{LF}} = N_{\ell}^{\mathrm{HF}} + \Delta_{\ell}^{\mathrm{LF}}\). The set \(\Delta_{\ell}^{\mathrm{LF}}\) is written, for convenience, as proportional to \(N_{\ell}^{\mathrm{HF}}\) by means of a parameter \(r_{\ell} \in \mathbb{R}^+_0\)
The set of samples \(\Delta_{\ell}^{\mathrm{LF}}\) is independent of \(N_{\ell}^{\mathrm{HF}}\), therefore the variance of the estimator can be written as (for further details see [GIE15])
The Pearson’s correlation coefficient between the HF and LF models is indicated by \(\rho_\ell\) in the previous equations. Assuming the vector \(r_\ell\) as a parameter, the variance is minimized per level, mimicking the standard control variate approach, and thus obtaining the optimal coefficient as \(\alpha_\ell = -\rho_\ell \sqrt{ \dfrac{ \mathbb{V}ar\left( Y^{\mathrm{HF}}_{\ell} \right) }{ \mathbb{V}ar\left( Y^{\mathrm{LF}}_{\ell} \right) }}\). By making use of the optimal coefficient \(\alpha_\ell\), it is possible to show that the variance \(\mathbb{V}ar\left(Y^{\mathrm{HF},\star}_{\ell}\right)\) is proportional to the variance \(\mathbb{V}ar\left(Y^{\mathrm{HF}}_{\ell}\right)\) through a factor \(\Lambda_{\ell}(r_\ell)\), which is an explicit function of the ratio \(r_\ell\):
Note that \(\Lambda_{\ell}(r_\ell)\) represents a penalty with respect to the classical control variate approach presented in Multifidelity Monte Carlo, which stems from the need to evaluate the unknown function \(\mathbb{E}\left[Y^{\mathrm{LF}}_{\ell}\right]\). However, the ratio \(r_\ell/(r_\ell+1)\) is dependent on the additional number of LF evaluations \(\Delta_{\ell}^{\mathrm{LF}}\), hence it is fair to assume that it can be made very close to unity by choosing an affordably large \(r_\ell\), i.e., \(\Delta_{\ell}^{\mathrm{LF}} >> N_{\ell}^{\mathrm{HF}}\).
The optimal sample allocation is determined taking into account the relative cost between the HF and LF models and their correlation (per level). In particular the optimization problem introduced in Eq. (40) is replaced by
where the optimal allocation is obtained as well as the optimal ratio \(r_\ell\). The cost per level includes now the sum of the HF and LF realization cost, therefore it can be expressed as \(\mathcal{C}_{\ell}^{\mathrm{eq}} = \mathcal{C}_{\ell}^{\mathrm{HF}} + \mathcal{C}_{\ell}^{\mathrm{LF}} (1+r_\ell)\).
If the cost ratio between the HF and LF model is \(w_{\ell} = \mathcal{C}_{\ell}^{\mathrm{HF}} / \mathcal{C}_{\ell}^{\mathrm{LF}}\) then the optimal ratio is
and the optimal allocation is
It is clear that the efficiency of the algorithm is related not only to the efficiency of the LF model, i.e. how fast a simulation runs with respect to the HF model, but also to the correlation between the LF and HF model.
\(Q_l\) correlations
A potential refinement of the previous approach [GEI17] consists in exploiting the QoI on each pair of levels, \(\ell\) and \(\ell-1\), to build a more correlated LF function. For instance, it is possible to use
and maximize the correlation between \(Y_\ell^{\mathrm{HF}}\) and \(\mathring{Y}^{\mathrm{LF}}_{\ell}\) through the coefficient \(\gamma_\ell\).
Formally the two formulations are completely equivalent if \(Y_\ell^{\mathrm{LF}}\) is replaced with \(\mathring{Y}^{\mathrm{LF}}_{\ell}\) in Eq. (47) and they can be linked through the two ratios
obtaining the following variance for the estimator
Therefore, a way to increase the variance reduction is to maximize the ratio \(\dfrac{\theta_\ell^2}{\tau_\ell}\) with respect to the parameter \(\gamma_\ell\). It is possible to solve analytically this maximization problem obtaining
The resulting optimal allocation of samples across levels and model forms is given by
Quasi-Monte Carlo (QMC)
Quasi-Monte Carlo methods are equal-weight quadrature rules to approximate \(\mathbb{E}\left[Q\right]\) with deterministically well-chosen sample points to beat the notoriously slow convergence of a method that uses random MC samples. They are of the form
which is seemingly identical to the form of the classic MC method from Eq. (36), however, the \(N\) \(s\)-dimensional points \(\boldsymbol{t}^{(i)}\) are now carefully chosen inside the domain \(\Xi \subset \mathbb{R}^d\). With carefully chosen we mean that the points have a low discrepancy \(D(\boldsymbol{t}^{(0)}, \boldsymbol{t}^{(1)}, \ldots, \boldsymbol{t}^{(N-1)})\). This discrepancy is important, because it directly appears in the error bound of a QMC method, i.e., we have the Koksma-Hlawka inequality [Nie92]
The QMC error thus consists of two parts: a factor that only depends on the point set (in particular, on the discrepancy of the point set) and a factor depending only on the function \(f\) we are trying to integrate (the so-called variation of the function \(f\)).
Some famous examples of low-discrepancy point sets are Sobol points [Sobol67], Halton points [HS64] and Hammersley points [Ham13]. The advantage of using such a low-discrepancy point set is faster convergence: classic theory states that a QMC method may converge like \((\log N)^d/N\), for sufficiently smooth functions \(f\), see [DP10]. Compare this to the classic MC method, that converges like \(1/\sqrt{N}\), and it is easy to see why QMC methods are so appealing.
Unfortunately, the classic QMC theory is not adequate in high dimensions (large \(d\)): for \((\log N)^d/N\) to be smaller than \(1/\sqrt{N}\), we require, for example, \(N > \exp(d)\), an unrealistically large number in high dimensions. Furthermore, in many problems, the variation \(V(f)\) is infinite, making the error bound in (51) practically useless.
Then, in 1995, a 360-dimensional integral originating from financial mathematics was computed very efficiently by Paskov and Traub, see [PT96]. This led to many new theoretical developments, including the notion of weighted function spaces and low effective dimension: although the problem is high-dimensional, not all dimensions are equally important. In the work by Sloan and Woźniakowski [SWozniakowski98], this decreasing importance is quantified in terms of weights \(\gamma_j\) associated to each dimension \(j\), and where one assumes \(\gamma_1 \geq \gamma_2 \geq \ldots \geq \gamma_d \geq 0\). Contemporary QMC analysis is then performed by analyzing the problem in a function space that incorporates these weights. A reinterpretation of (51) in the weighted space setting with weights \(\boldsymbol{\gamma}\) is then
where \(e_{\boldsymbol{\gamma}}\) is the so-called worst-case error, and \(\|f\|_{\boldsymbol{\gamma}}\) is the norm of the function in the weighted function space. The question then becomes one of (strong) tractability: under which conditions on the weights is the worst-case error bounded independent of the dimension \(d\)? The philosophy of modern QMC is therefore to choose the weights according to the problem at hand, and then construct a QMC method that yields good performance for all functions that belong to this weighted function space, see [DP10].
QMC methods come in two major flavors: lattice rules and digital nets. We will now briefly discuss these two construction methods.
Rank-1 lattice rules and sequences
An \(N\)-point rank-1 lattice rule in \(d\) dimensions generates points according to
where \(\{\;\cdot\;\}\) denotes the fractional part, i.e., \(\{x\} = x - \lceil x \rceil\), and where \(\boldsymbol{z} = (z_1, z_2, \ldots, z_d)\) is an \(d\)-dimensional vector with integers, called the generating vector. Rank-1 lattices were introduced by Korobov [Kor59] and Hlawka [Hla62], as the method of good lattice points.
The performance of the lattice rule depends critically on the choice of the generating vector \(\boldsymbol{z}\). We assume that \(z \in \mathbb{U}_N^d\), where \(\mathbb{U}_N = \{ z \in \mathbb{Z} : 1 \leq z \leq N - 1 \;\text{and}\; \mathrm{gcd}(z, N) = 1\}\), to ensure that every one-dimensional projection of the \(N\) points on one of the coordinate axes has \(N\) distinct values. It can be shown that the number of elements inside the set \(\mathbb{U}_N\) is given by the Euler totient function \(\varphi(N)\). For number theoretical reasons, \(N\) is usually restricted to be a prime number, such that the number of elements is \(\varphi(N) = N-1\). In that case, there are an astounding \((N - 1)^d\) possible choices for the generating vector \(\boldsymbol{z}\). Since it is impossible to perform an exhaustive search over all possible choices for large \(N\) and \(s\) to find the best possible generating vector \(\boldsymbol{z}\), we resort to construction schemes that deliver good choices for \(\boldsymbol{z}\). An example of such a scheme is the component-by-component (CBC) construction [Kor63, SJ94]. The algorithm works as follows:
Set \(z_1=1\).
With \(z_1\) fixed, pick \(z_2 \in \mathbb{U}_N\) such that \(e_{\boldsymbol{\gamma}}(z_1, z_2)\) is minimized.
With \(z_1\) and \(z_2\) fixed, pick \(z_3 \in \mathbb{U}_N\) such that \(e_{\boldsymbol{\gamma}}(z_1, z_2, z_3)\) is minimized.
…
Hence, this algorithm constructs the components of the generating vector for the lattice rule one at a time: the \((j + 1)\)th component is obtained by successive one-dimensional searches, with the previous \(j\) components kept fixed. It can be proven that the CBC algorithm constructs generating vectors that, when used in a lattice rule, achieve the desired convergence close to \(1/N\), in some weighted function space, see [Kuo03].
For some particular choices of the weights \(\boldsymbol{\gamma}\) (called product weights), the cost of the CBC algorithm is \(O(d N \log N )\) operations, i.e., linear in the dimension \(d\) and almost linear in the number of points \(N\), due to a fast CBC construction by Nuyens and Cools, see [CKN06, NC06]. The idea for the fast construction is that the CBC construction requires the evaluation of a matrix-vector multiplication with a circulant matrix, hence reducing the cost of the matrix-vector product from \(O(N^2)\) to \(O(N \log N)\) by using FFT.
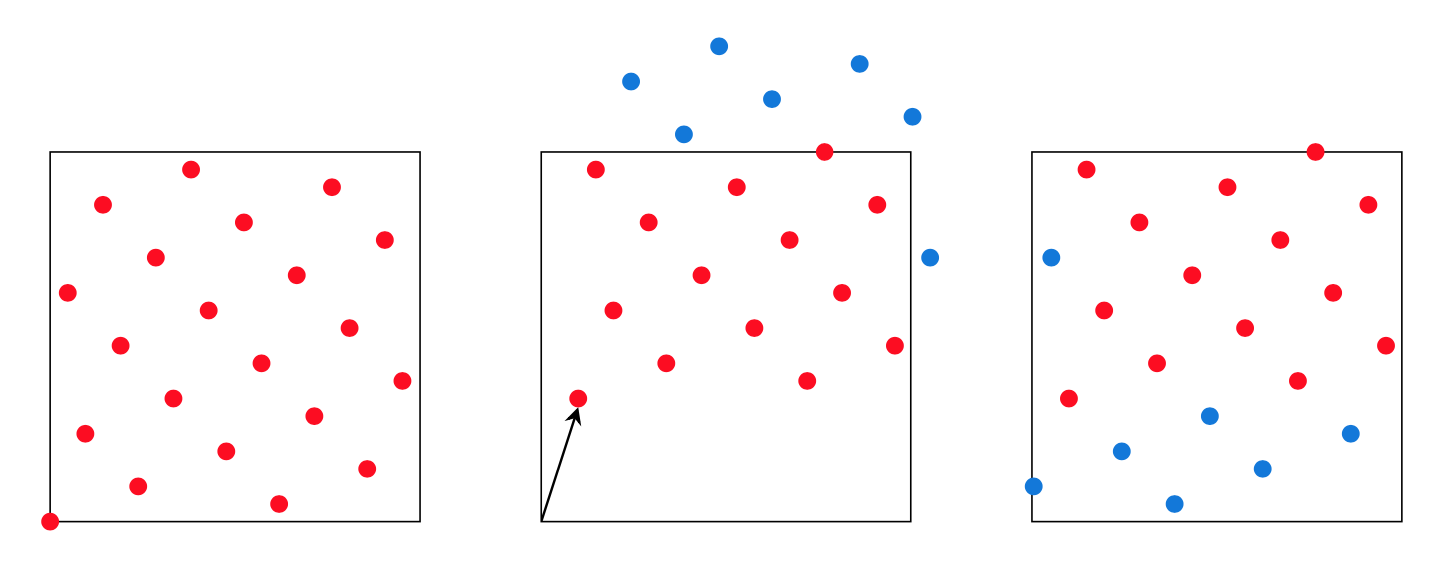
Fig. 64 Applying a \((1/10, 1/3)\)-shift to a 21-point Fibonacci lattice in two dimensions. Take the original lattice (left), apply a random shift (middle) and wrap the points back onto the unit square (right).
The lattice points given in (52) can be randomized by adding a random shift vector. If \(\Delta\) is a \(d\)-dimensional vector of standard normal random variables, we construct the shifted lattice points as
This procedure is illustrated in Fig. 64. Note that the first untransformed point in the sequence will be \(\boldsymbol{t}^{(0)} = (0, 0, \ldots, 0)\).
For the lattice points to be practically useful, we would like to transform the lattice rule into a lattice sequence, that allows us to generate well-distributed points for an arbitrary number of points \(N\). To this end, Eq. (52) is adapted to
where \(\phi_b(i)\) denotes the so-called radical inverse function in base \(b\) (usually, \(b = 2\)). This function transforms a number \(i = (\ldots i_2i_1)_b\) in its base-\(b\) representation to \(\phi_b(i) = (0.i_1i_2\ldots)_b\). Note that the radical inverse function agrees with the original formulation when \(N = b^m\) for any \(m \geq 0\).
Digital nets and sequences
Digital nets and sequences were introduced by Niederreiter, building upon earlier work by Sobol and Faure [Nie87]. In the digital construction scheme, a sequence in \(d\) dimensions generates points \(\boldsymbol{t}^{(i)} = (t_{i, 0}, t_{i, 1}, \ldots, t_{i, d})\), where the \(j\)th component \(t_{i, j}\) is constructed as follows:
Write \(i\) in its base-\(b\) representation, i.e.,
Compute the matrix-vector product
where all additions and multiplications are performed in base \(b\).
Set the \(j\)th component of the \(i\)th points to
The matrices \(C_j\), \(j=1, 2, \ldots, d\) are known as generating matrices, see [DP10].
We can encode the generating matrices as an integer matrix as follows. The
number of rows in the matrix determines the maximum dimension of the lattice
rule. The number of columns in the matrix determines the log2 of the maximum
number of points. An integer on the \(j\)th row and \(m\)th column
encodes the \(m\)th column of the \(j\)th generating matrix
\(C_j\). Since the \(m\)th column of \(C_j\) is a collection of
0’s and 1’s, it can be represented as an integer with \(t\) bits, where
\(t\) is the number of rows in the \(j\)th generating matrix
\(C_j\). By default, the encoding assumes the integers are stored with
least significant bit first (LSB), so that the first integer on the \(j\)th row is 1. This LSB representation has two advantages.
The integers can be reused if the number of bits \(t\) in the representation changes.
It generally leads to smaller, human-readable numbers in the first few entries.
The Sobol sequence is a particularly famous example of a digital net [Sobol67]. A computer implementation of a Sobol sequence generator in Fortran 77 was given by Bratley and Fox [BF88] as Algorithm 659. This implementation allowed points of up to 40 dimensions. It was extended by Joe and Kuo to allow up to 1111 dimensions in [JK03] and up to 21201 dimensions in [JK08]. In the Dakota implementation of the algorithm outlined above, we use the iterative construction from Antonov and Saleev [AS79], that generates the points in Gray code ordering. Knowing the current point with (Gray code) index \(n\), the next point with index \(n + 1\) is obtained by XOR’ing the current point with the \(k\)th column of the \(j\)th generating matrix, i.e.,
where \(k\) is the rightmost zero-bit of \(n\) (the position of the bit that will change from index \(n\) to \(n+1\) in Gray code).
The digital net points can be randomized by adding a digital shift vector. If
\(\Delta\) is a \(d\)-dimensional vector of standard normal random
variables, we construct the shifted lattice points as
\(\boldsymbol{t}^{(i)} \otimes \Delta\), where \(\otimes\) is the
element-wise \(b\)-ary addition (or XOR) operator, see [DP10].
Note that the first untransformed point in the sequence will be
\(\boldsymbol{t}^{(0)} = (0, 0, \ldots, 0)\).
Ideally, the digital net should preserve the structure of the points after randomization. This can be achieved by scrambling the digital net. Scrambling can also improve the rate of convergence of a method that uses these scrambled points to compute the mean of the model response. Owen’s scrambling [Owe98] is the most well-known scrambling technique. A particular variant is linear matrix scrambling, see [Matouvsek98], which is implemented in Dakota. In linear matrix scrambling, we left-multiply each generating matrix with a lower-triangular random scramble matrix with 1s on the diagonal, i.e.,
1 0 0 0 0
x 1 0 0 0
x x 1 0 0
x x x 1 0
x x x x 1
Finally, for the digital net points to be practically useful, we would like to transform the digital net into a digital sequence, that allows us to generate well-distributed points for an arbitrary number of points \(N\). One way to do this is to generate the points in Gray code ordering, as discussed above.