|
Dakota
Version 6.19
Explore and Predict with Confidence
|
|
Dakota
Version 6.19
Explore and Predict with Confidence
|
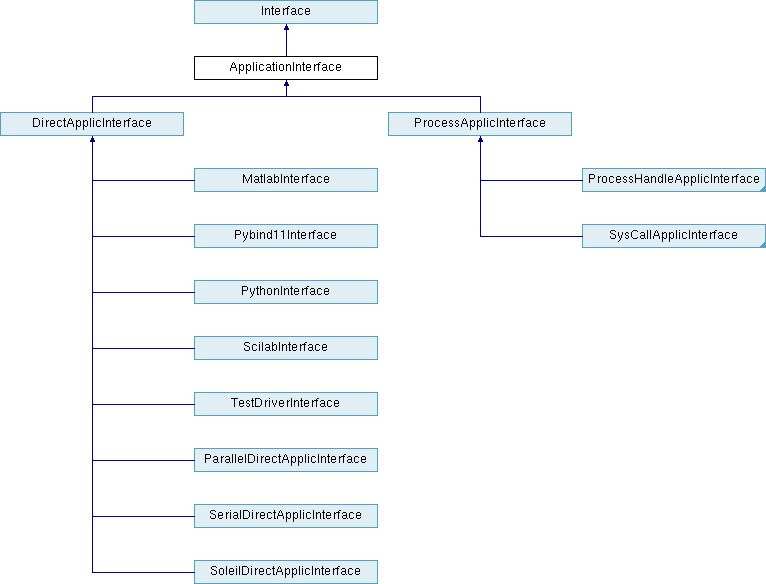
Derived class within the interface class hierarchy for supporting interfaces to simulation codes. More...
Public Member Functions | |
| ApplicationInterface (const ProblemDescDB &problem_db) | |
| constructor | |
| ~ApplicationInterface () | |
| destructor | |
 Public Member Functions inherited from Interface Public Member Functions inherited from Interface | |
| Interface () | |
| default constructor More... | |
| Interface (ProblemDescDB &problem_db) | |
| standard constructor for envelope More... | |
| Interface (const Interface &interface_in) | |
| copy constructor More... | |
| virtual | ~Interface () |
| destructor | |
| Interface | operator= (const Interface &interface_in) |
| assignment operator | |
| virtual int | minimum_points (bool constraint_flag) const |
| returns the minimum number of points required to build a particular ApproximationInterface (used by DataFitSurrModels). | |
| virtual int | recommended_points (bool constraint_flag) const |
| returns the recommended number of points required to build a particular ApproximationInterface (used by DataFitSurrModels). | |
| virtual void | active_model_key (const Pecos::ActiveKey &key) |
| activate an approximation state based on its key | |
| virtual void | clear_model_keys () |
| reset initial state by removing all model keys for an approximation | |
| virtual void | approximation_function_indices (const SizetSet &approx_fn_indices) |
| set the (currently active) approximation function index set | |
| virtual void | update_approximation (const Variables &vars, const IntResponsePair &response_pr) |
| updates the anchor point for an approximation | |
| virtual void | update_approximation (const RealMatrix &samples, const IntResponseMap &resp_map) |
| updates the current data points for an approximation | |
| virtual void | update_approximation (const VariablesArray &vars_array, const IntResponseMap &resp_map) |
| updates the current data points for an approximation | |
| virtual void | append_approximation (const Variables &vars, const IntResponsePair &response_pr) |
| appends a single point to an existing approximation | |
| virtual void | append_approximation (const RealMatrix &samples, const IntResponseMap &resp_map) |
| appends multiple points to an existing approximation | |
| virtual void | append_approximation (const VariablesArray &vars_array, const IntResponseMap &resp_map) |
| appends multiple points to an existing approximation | |
| virtual void | append_approximation (const IntVariablesMap &vars_map, const IntResponseMap &resp_map) |
| appends multiple points to an existing approximation | |
| virtual void | replace_approximation (const IntResponsePair &response_pr) |
| replace the response for a single point within an existing approximation | |
| virtual void | replace_approximation (const IntResponseMap &resp_map) |
| replace responses for multiple points within an existing approximation | |
| virtual void | track_evaluation_ids (bool track) |
| assigns trackEvalIds to activate tracking of evaluation ids within surrogate data, enabling id-based lookups for data replacement | |
| virtual void | build_approximation (const RealVector &c_l_bnds, const RealVector &c_u_bnds, const IntVector &di_l_bnds, const IntVector &di_u_bnds, const RealVector &dr_l_bnds, const RealVector &dr_u_bnds) |
| builds the approximation | |
| virtual void | export_approximation () |
| export the approximation to disk | |
| virtual void | rebuild_approximation (const BitArray &rebuild_fns) |
| rebuilds the approximation after a data update | |
| virtual void | pop_approximation (bool save_data) |
| removes data from last append from the approximation | |
| virtual void | push_approximation () |
| retrieves approximation data from a previous state (negates pop) | |
| virtual bool | push_available () |
| queries the approximation for the ability to retrieve a previous increment | |
| virtual void | finalize_approximation () |
| finalizes the approximation by applying all trial increments | |
| virtual void | combine_approximation () |
| combine the current approximation with previously stored data sets | |
| virtual void | combined_to_active (bool clear_combined=true) |
| promote the combined approximation to the currently active one | |
| virtual void | clear_inactive () |
| clear inactive approximation data | |
| virtual bool | advancement_available () |
| query for available advancements in approximation resolution controls | |
| virtual bool | formulation_updated () const |
| query for change in approximation formulation | |
| virtual void | formulation_updated (bool update) |
| assign an updated status for approximation formulation to force rebuild | |
| virtual Real2DArray | cv_diagnostics (const StringArray &metric_types, unsigned num_folds) |
| approximation cross-validation quality metrics per response function | |
| virtual RealArray | challenge_diagnostics (const String &metric_type, const RealMatrix &challenge_pts) |
| approximation challenge data metrics per response function | |
| virtual void | clear_current_active_data () |
| clears current data from an approximation interface | |
| virtual void | clear_active_data () |
| clears all data from an approximation interface | |
| virtual SharedApproxData & | shared_approximation () |
| retrieve the SharedApproxData within an ApproximationInterface | |
| virtual std::vector< Approximation > & | approximations () |
| retrieve the Approximations within an ApproximationInterface | |
| virtual const Pecos::SurrogateData & | approximation_data (size_t fn_index) |
| retrieve the approximation data from a particular Approximation within an ApproximationInterface | |
| virtual const RealVectorArray & | approximation_coefficients (bool normalized=false) |
| retrieve the approximation coefficients from each Approximation within an ApproximationInterface | |
| virtual void | approximation_coefficients (const RealVectorArray &approx_coeffs, bool normalized=false) |
| set the approximation coefficients within each Approximation within an ApproximationInterface | |
| virtual const RealVector & | approximation_variances (const Variables &vars) |
| retrieve the approximation variances from each Approximation within an ApproximationInterface | |
| virtual const StringArray & | analysis_drivers () const |
| retrieve the analysis drivers specification for application interfaces | |
| virtual const String2DArray & | analysis_components () const |
| retrieve the analysis components, if available | |
| virtual void | discrepancy_emulation_mode (short mode) |
| set discrepancy emulation mode used for approximating response differences | |
| virtual void | file_cleanup () const |
| clean up any interface parameter/response files when aborting | |
| IntResponseMap & | response_map () |
| return rawResponseMap | |
| void | cache_unmatched_response (int raw_id) |
| migrate an unmatched response record from rawResponseMap to cachedResponseMap | |
| void | cache_unmatched_responses () |
| migrate all remaining response records from rawResponseMap to cachedResponseMap | |
| void | assign_rep (std::shared_ptr< Interface > interface_rep) |
| assign letter or replace existing letter with a new one More... | |
| void | assign_rep (Interface *interface_rep, bool ref_count_incr=false) |
| assign letter or replace existing letter with a new one DEPRECATED, but left for library mode clients to migrate: transfers memory ownership to the contained shared_ptr; ref_count_incr is ignored More... | |
| unsigned short | interface_type () const |
| returns the interface type | |
| const String & | interface_id () const |
| returns the interface identifier | |
| int | evaluation_id () const |
| returns the value of the (total) evaluation id counter for the interface | |
| void | fine_grained_evaluation_counters (size_t num_fns) |
| set fineGrainEvalCounters to true and initialize counters if needed | |
| void | init_evaluation_counters (size_t num_fns) |
| initialize fine grained evaluation counters, sizing if needed | |
| void | set_evaluation_reference () |
| set evaluation count reference points for the interface | |
| void | print_evaluation_summary (std::ostream &s, bool minimal_header, bool relative_count) const |
| print an evaluation summary for the interface | |
| bool | multi_proc_eval () const |
| returns a flag signaling the use of multiprocessor evaluation partitions | |
| bool | iterator_eval_dedicated_master () const |
| returns a flag signaling the use of a dedicated master processor at the iterator-evaluation scheduling level | |
| bool | is_null () const |
| function to check interfaceRep (does this envelope contain a letter?) | |
| std::shared_ptr< Interface > | interface_rep () |
| function to return the letter | |
| void | eval_tag_prefix (const String &eval_id_str, bool append_iface_id=true) |
| set the evaluation tag prefix (does not recurse) More... | |
Protected Member Functions | |
| void | init_communicators (const IntArray &message_lengths, int max_eval_concurrency) |
| allocate communicator partitions for concurrent evaluations within an iterator and concurrent multiprocessor analyses within an evaluation. | |
| void | set_communicators (const IntArray &message_lengths, int max_eval_concurrency) |
| set the local parallel partition data for an interface (the partitions are already allocated in ParallelLibrary). | |
| void | init_serial () |
| int | asynch_local_evaluation_concurrency () const |
| return asynchLocalEvalConcurrency | |
| short | interface_synchronization () const |
| return interfaceSynchronization | |
| bool | evaluation_cache () const |
| return evalCacheFlag | |
| bool | restart_file () const |
| return evalCacheFlag | |
| String | final_eval_id_tag (int fn_eval_id) |
| form and return the final evaluation ID tag, appending iface ID if needed | |
| void | map (const Variables &vars, const ActiveSet &set, Response &response, bool asynch_flag=false) |
| Provides a "mapping" of variables to responses using a simulation. Protected due to Interface letter-envelope idiom. More... | |
| void | manage_failure (const Variables &vars, const ActiveSet &set, Response &response, int failed_eval_id) |
| manages a simulation failure using abort/retry/recover/continuation | |
| const IntResponseMap & | synchronize () |
| executes a blocking schedule for asynchronous evaluations in the beforeSynchCorePRPQueue and returns all jobs More... | |
| const IntResponseMap & | synchronize_nowait () |
| executes a nonblocking schedule for asynchronous evaluations in the beforeSynchCorePRPQueue and returns a partial set of completed jobs More... | |
| void | serve_evaluations () |
| run on evaluation servers to serve the iterator master More... | |
| void | stop_evaluation_servers () |
| used by the iterator master to terminate evaluation servers More... | |
| bool | check_multiprocessor_analysis (bool warn) |
| checks on multiprocessor analysis configuration | |
| bool | check_asynchronous (bool warn, int max_eval_concurrency) |
| checks on asynchronous configuration (for direct interfaces) | |
| bool | check_multiprocessor_asynchronous (bool warn, int max_eval_concurrency) |
| checks on asynchronous settings for multiprocessor partitions | |
| String | final_batch_id_tag () |
| form and return the final batch ID tag | |
| virtual void | derived_map (const Variables &vars, const ActiveSet &set, Response &response, int fn_eval_id) |
| Called by map() and other functions to execute the simulation in synchronous mode. The portion of performing an evaluation that is specific to a derived class. | |
| virtual void | derived_map_asynch (const ParamResponsePair &pair) |
| Called by map() and other functions to execute the simulation in asynchronous mode. The portion of performing an asynchronous evaluation that is specific to a derived class. | |
| virtual void | wait_local_evaluations (PRPQueue &prp_queue) |
| For asynchronous function evaluations, this method is used to detect completion of jobs and process their results. It provides the processing code that is specific to derived classes. This version waits for at least one completion. | |
| virtual void | test_local_evaluations (PRPQueue &prp_queue) |
| For asynchronous function evaluations, this method is used to detect completion of jobs and process their results. It provides the processing code that is specific to derived classes. This version is nonblocking and will return without any completions if none are immediately available. | |
| virtual void | init_communicators_checks (int max_eval_concurrency) |
| perform construct-time error checks on the parallel configuration More... | |
| virtual void | set_communicators_checks (int max_eval_concurrency) |
| perform run-time error checks on the parallel configuration More... | |
| void | master_dynamic_schedule_analyses () |
| blocking dynamic schedule of all analyses within a function evaluation using message passing More... | |
| void | serve_analyses_synch () |
| serve the master analysis scheduler and manage one synchronous analysis job at a time More... | |
| virtual int | synchronous_local_analysis (int analysis_id) |
| Execute a particular analysis (identified by analysis_id) synchronously on the local processor. Used for the derived class specifics within ApplicationInterface::serve_analyses_synch(). | |
| Protected Member Functions inherited from Interface | |
| Interface (BaseConstructor, const ProblemDescDB &problem_db) | |
| constructor initializes the base class part of letter classes (BaseConstructor overloading avoids infinite recursion in the derived class constructors - Coplien, p. 139) More... | |
| Interface (NoDBBaseConstructor, size_t num_fns, short output_level) | |
| constructor initializes the base class part of letter classes (NoDBBaseConstructor used for on the fly instantiations without a DB) | |
| void | init_algebraic_mappings (const Variables &vars, const Response &response) |
| Define algebraicACVIndices, algebraicACVIds, and algebraicFnIndices. | |
| void | asv_mapping (const ActiveSet &total_set, ActiveSet &algebraic_set, ActiveSet &core_set) |
| define the evaluation requirements for algebraic_mappings() (algebraic_set) and the core Application/Approximation mapping (core_set) from the total Interface evaluation requirements (total_set) | |
| void | asv_mapping (const ActiveSet &algebraic_set, ActiveSet &total_set) |
| map an algebraic ASV back to original total ordering for asynch recovery | |
| void | algebraic_mappings (const Variables &vars, const ActiveSet &algebraic_set, Response &algebraic_response) |
| evaluate the algebraic_response using the AMPL solver library and the data extracted from the algebraic_mappings file | |
| void | response_mapping (const Response &algebraic_response, const Response &core_response, Response &total_response) |
| combine the response from algebraic_mappings() with the response from derived_map() to create the total response More... | |
Protected Attributes | |
| ParallelLibrary & | parallelLib |
| reference to the ParallelLibrary object used to manage MPI partitions for the concurrent evaluations and concurrent analyses parallelism levels | |
| bool | batchEval |
| flag indicating usage of batch evaluation facilities, where a set of jobs is launched and scheduled as a unit rather than individually | |
| bool | asynchFlag |
| flag indicating usage of asynchronous evaluation | |
| int | batchIdCntr |
| maintain a count of the batches | |
| bool | suppressOutput |
| flag for suppressing output on slave processors | |
| int | evalCommSize |
| size of evalComm | |
| int | evalCommRank |
| processor rank within evalComm | |
| int | evalServerId |
| evaluation server identifier | |
| bool | eaDedMasterFlag |
| flag for dedicated master partitioning at ea level | |
| int | analysisCommSize |
| size of analysisComm | |
| int | analysisCommRank |
| processor rank within analysisComm | |
| int | analysisServerId |
| analysis server identifier | |
| int | numAnalysisServers |
| current number of analysis servers | |
| bool | multiProcAnalysisFlag |
| flag for multiprocessor analysis partitions | |
| bool | asynchLocalAnalysisFlag |
| flag for asynchronous local parallelism of analyses | |
| int | asynchLocalAnalysisConcurrency |
| limits the number of concurrent analyses in asynchronous local scheduling and specifies hybrid concurrency when message passing | |
| int | asynchLocalEvalConcSpec |
| user specification for asynchronous local evaluation concurrency | |
| int | asynchLocalAnalysisConcSpec |
| user specification for asynchronous local analysis concurrency | |
| int | numAnalysisDrivers |
| the number of analysis drivers used for each function evaluation (from the analysis_drivers interface specification) | |
| IntSet | completionSet |
| the set of completed fn_eval_id's populated by wait_local_evaluations() and test_local_evaluations() | |
| String | failureMessage |
| base message for managing failed evals; will be followed with more details in screen output | |
| Protected Attributes inherited from Interface | |
| unsigned short | interfaceType |
| the interface type: enum for system, fork, direct, grid, or approximation | |
| String | interfaceId |
| the interface specification identifier string from the DAKOTA input file | |
| bool | algebraicMappings |
| flag for the presence of algebraic_mappings that define the subset of an Interface's parameter to response mapping that is explicit and algebraic. | |
| bool | coreMappings |
| flag for the presence of non-algebraic mappings that define the core of an Interface's parameter to response mapping (using analysis_drivers for ApplicationInterface or functionSurfaces for ApproximationInterface). | |
| short | outputLevel |
| output verbosity level: {SILENT,QUIET,NORMAL,VERBOSE,DEBUG}_OUTPUT | |
| int | currEvalId |
| identifier for the current evaluation, which may differ from the evaluation counters in the case of evaluation scheduling; used on iterator master as well as server processors. Currently, this is set prior to all invocations of derived_map() for all processors. | |
| bool | fineGrainEvalCounters |
| controls use of fn val/grad/hess counters for detailed evaluation report | |
| int | evalIdCntr |
| total interface evaluation counter | |
| int | newEvalIdCntr |
| new (non-duplicate) interface evaluation counter | |
| int | evalIdRefPt |
| iteration reference point for evalIdCntr | |
| int | newEvalIdRefPt |
| iteration reference point for newEvalIdCntr | |
| IntArray | fnValCounter |
| number of value evaluations by resp fn | |
| IntArray | fnGradCounter |
| number of gradient evaluations by resp fn | |
| IntArray | fnHessCounter |
| number of Hessian evaluations by resp fn | |
| IntArray | newFnValCounter |
| number of new value evaluations by resp fn | |
| IntArray | newFnGradCounter |
| number of new gradient evaluations by resp fn | |
| IntArray | newFnHessCounter |
| number of new Hessian evaluations by resp fn | |
| IntArray | fnValRefPt |
| iteration reference point for fnValCounter | |
| IntArray | fnGradRefPt |
| iteration reference point for fnGradCounter | |
| IntArray | fnHessRefPt |
| iteration reference point for fnHessCounter | |
| IntArray | newFnValRefPt |
| iteration reference point for newFnValCounter | |
| IntArray | newFnGradRefPt |
| iteration reference point for newFnGradCounter | |
| IntArray | newFnHessRefPt |
| iteration reference point for newFnHessCounter | |
| IntResponseMap | rawResponseMap |
| Set of responses returned by either a blocking or nonblocking schedule. More... | |
| IntResponseMap | cachedResponseMap |
| Set of available asynchronous responses completed within a blocking or nonblocking scheduler that cannot be processed in a higher level context and need to be stored for later. | |
| StringArray | fnLabels |
| response function descriptors (used in print_evaluation_summary() and derived direct interface classes); initialized in map() functions due to potential updates after construction | |
| bool | multiProcEvalFlag |
| flag for multiprocessor evaluation partitions (evalComm) | |
| bool | ieDedMasterFlag |
| flag for dedicated master partitioning at the iterator level | |
| String | evalTagPrefix |
| set of period-delimited evaluation ID tags to use in evaluation tagging | |
| bool | appendIfaceId |
| whether to append the interface ID to the prefix during map (default true) | |
| String2DArray | analysisComponents |
| Analysis components for interface types that support them. | |
Private Member Functions | |
| bool | duplication_detect (const Variables &vars, Response &response, bool asynch_flag) |
| checks data_pairs and beforeSynchCorePRPQueue to see if the current evaluation request has already been performed or queued More... | |
| void | init_default_asv (size_t num_fns) |
| initialize default ASV if needed; this is done at run time due to post-construct time Response size changes. More... | |
| void | master_dynamic_schedule_evaluations () |
| blocking dynamic schedule of all evaluations in beforeSynchCorePRPQueue using message passing on a dedicated master partition; executes on iteratorComm master More... | |
| void | peer_static_schedule_evaluations () |
| blocking static schedule of all evaluations in beforeSynchCorePRPQueue using message passing on a peer partition; executes on iteratorComm master More... | |
| void | peer_dynamic_schedule_evaluations () |
| blocking dynamic schedule of all evaluations in beforeSynchCorePRPQueue using message passing on a peer partition; executes on iteratorComm master More... | |
| void | asynchronous_local_evaluations (PRPQueue &prp_queue) |
| perform all jobs in prp_queue using asynchronous approaches on the local processor More... | |
| void | synchronous_local_evaluations (PRPQueue &prp_queue) |
| perform all jobs in prp_queue using synchronous approaches on the local processor More... | |
| void | master_dynamic_schedule_evaluations_nowait () |
| execute a nonblocking dynamic schedule in a master-slave partition More... | |
| void | peer_static_schedule_evaluations_nowait () |
| execute a nonblocking static schedule in a peer partition More... | |
| void | peer_dynamic_schedule_evaluations_nowait () |
| execute a nonblocking dynamic schedule in a peer partition More... | |
| void | asynchronous_local_evaluations_nowait (PRPQueue &prp_queue) |
| launch new jobs in prp_queue asynchronously (if capacity is available), perform nonblocking query of all running jobs, and process any completed jobs (handles both local master- and local peer-scheduling cases) More... | |
| void | broadcast_evaluation (const ParamResponsePair &pair) |
| convenience function for broadcasting an evaluation over an evalComm | |
| void | broadcast_evaluation (int fn_eval_id, const Variables &vars, const ActiveSet &set) |
| convenience function for broadcasting an evaluation over an evalComm | |
| void | send_evaluation (PRPQueueIter &prp_it, size_t buff_index, int server_id, bool peer_flag) |
| helper function for sending sendBuffers[buff_index] to server | |
| void | receive_evaluation (PRPQueueIter &prp_it, size_t buff_index, int server_id, bool peer_flag) |
| helper function for processing recvBuffers[buff_index] within scheduler | |
| void | launch_asynch_local (PRPQueueIter &prp_it) |
| launch an asynchronous local evaluation from a queue iterator | |
| void | launch_asynch_local (MPIUnpackBuffer &recv_buffer, int fn_eval_id) |
| launch an asynchronous local evaluation from a receive buffer | |
| void | process_asynch_local (int fn_eval_id) |
| process a completed asynchronous local evaluation | |
| void | process_synch_local (PRPQueueIter &prp_it) |
| process a completed synchronous local evaluation | |
| void | assign_asynch_local_queue (PRPQueue &local_prp_queue, PRPQueueIter &local_prp_iter) |
| helper function for creating an initial active local queue by launching asynch local jobs from local_prp_queue, as limited by server capacity | |
| void | assign_asynch_local_queue_nowait (PRPQueue &local_prp_queue, PRPQueueIter &local_prp_iter) |
| helper function for updating an active local queue by backfilling asynch local jobs from local_prp_queue, as limited by server capacity | |
| size_t | test_local_backfill (PRPQueue &assign_queue, PRPQueueIter &assign_iter) |
| helper function for testing active asynch local jobs and then backfilling | |
| size_t | test_receives_backfill (PRPQueueIter &assign_iter, bool peer_flag) |
| helper function for testing receive requests and then backfilling jobs | |
| void | serve_evaluations_synch () |
| serve the evaluation message passing schedulers and perform one synchronous evaluation at a time More... | |
| void | serve_evaluations_synch_peer () |
| serve the evaluation message passing schedulers and perform one synchronous evaluation at a time as part of the 1st peer More... | |
| void | serve_evaluations_asynch () |
| serve the evaluation message passing schedulers and manage multiple asynchronous evaluations More... | |
| void | serve_evaluations_asynch_peer () |
| serve the evaluation message passing schedulers and perform multiple asynchronous evaluations as part of the 1st peer More... | |
| void | set_evaluation_communicators (const IntArray &message_lengths) |
| convenience function for updating the local evaluation partition data following ParallelLibrary::init_evaluation_communicators(). | |
| void | set_analysis_communicators () |
| convenience function for updating the local analysis partition data following ParallelLibrary::init_analysis_communicators(). | |
| void | init_serial_evaluations () |
| set concurrent evaluation configuration for serial operations | |
| void | init_serial_analyses () |
| set concurrent analysis configuration for serial operations (e.g., for local executions on a dedicated master) | |
| const ParamResponsePair & | get_source_pair (const Variables &target_vars) |
| convenience function for the continuation approach in manage_failure() for finding the nearest successful "source" evaluation to the failed "target" | |
| void | continuation (const Variables &target_vars, const ActiveSet &set, Response &response, const ParamResponsePair &source_pair, int failed_eval_id) |
| performs a 0th order continuation method to step from a successful "source" evaluation to the failed "target". Invoked by manage_failure() for failAction == "continuation". | |
| void | common_input_filtering (const Variables &vars) |
| common input filtering operations, e.g. mesh movement | |
| void | common_output_filtering (Response &response) |
| common output filtering operations, e.g. data filtering | |
Private Attributes | |
| int | worldSize |
| size of MPI_COMM_WORLD | |
| int | worldRank |
| processor rank within MPI_COMM_WORLD | |
| int | iteratorCommSize |
| size of iteratorComm | |
| int | iteratorCommRank |
| processor rank within iteratorComm | |
| bool | ieMessagePass |
| flag for message passing at ie scheduling level | |
| int | numEvalServers |
| current number of evaluation servers | |
| int | numEvalServersSpec |
| user specification for number of evaluation servers | |
| int | procsPerEvalSpec |
| user specification for processors per analysis servers | |
| bool | eaMessagePass |
| flag for message passing at ea scheduling level | |
| int | numAnalysisServersSpec |
| user spec for number of analysis servers | |
| int | procsPerAnalysisSpec |
| user specification for processors per analysis servers | |
| int | lenVarsMessage |
| length of a MPIPackBuffer containing a Variables object; computed in Model::init_communicators() | |
| int | lenVarsActSetMessage |
| length of a MPIPackBuffer containing a Variables object and an ActiveSet object; computed in Model::init_communicators() | |
| int | lenResponseMessage |
| length of a MPIPackBuffer containing a Response object; computed in Model::init_communicators() | |
| int | lenPRPairMessage |
| length of a MPIPackBuffer containing a ParamResponsePair object; computed in Model::init_communicators() | |
| short | evalScheduling |
| user specification of evaluation scheduling algorithm: {DEFAULT,MASTER,PEER_DYNAMIC,PEER_STATIC}_SCHEDULING. Used for manual overrides of auto-configure logic in ParallelLibrary::resolve_inputs(). | |
| short | analysisScheduling |
| user specification of analysis scheduling algorithm: {DEFAULT,MASTER,PEER}_SCHEDULING. Used for manual overrides of the auto-configure logic in ParallelLibrary::resolve_inputs(). | |
| int | asynchLocalEvalConcurrency |
| limits the number of concurrent evaluations in asynchronous local scheduling and specifies hybrid concurrency when message passing | |
| bool | asynchLocalEvalStatic |
| whether the asynchronous local evaluations are to be performed with a static schedule (default false) | |
| BitArray | localServerAssigned |
| array with one bit per logical "server" indicating whether a job is currently running on the server (used for asynch local static schedules) | |
| short | interfaceSynchronization |
| interface synchronization specification: synchronous (default) or asynchronous | |
| bool | headerFlag |
| used by synchronize_nowait to manage header output frequency (since this function may be called many times prior to any completions) | |
| bool | asvControlFlag |
| used to manage a user request to deactivate the active set vector control. true = modify the ASV each evaluation as appropriate (default); false = ASV values are static so that the user need not check them on each evaluation. | |
| bool | evalCacheFlag |
| used to manage a user request to deactivate the function evaluation cache (i.e., queries and insertions using the data_pairs cache). | |
| bool | nearbyDuplicateDetect |
| flag indicating optional usage of tolerance-based duplication detection (less efficient, but helpful when experiencing restart cache misses) | |
| Real | nearbyTolerance |
| tolerance value for tolerance-based duplication detection | |
| bool | restartFileFlag |
| used to manage a user request to deactivate the restart file (i.e., insertions into write_restart). | |
| SharedResponseData | sharedRespData |
| SharedResponseData of associated Response. | |
| String | gradientType |
| type of gradients present in associated Response | |
| String | hessianType |
| type of Hessians present in associated Response | |
| IntSet | gradMixedAnalyticIds |
| IDs of analytic gradients when mixed gradients present. | |
| IntSet | hessMixedAnalyticIds |
| IDs of analytic gradients when mixed gradients present. | |
| ShortArray | defaultASV |
| the static ASV values used when the user has selected asvControl = off | |
| String | failAction |
| mitigation action for captured simulation failures: abort, retry, recover, or continuation | |
| int | failRetryLimit |
| limit on the number of retries for the retry failAction | |
| RealVector | failRecoveryFnVals |
| the dummy function values used for the recover failAction | |
| IntResponseMap | historyDuplicateMap |
| used to bookkeep asynchronous evaluations which duplicate data_pairs evaluations. Map key is evalIdCntr, map value is corresponding response. | |
| std::map< int, std::pair< PRPQueueHIter, Response > > | beforeSynchDuplicateMap |
| used to bookkeep evalIdCntr, beforeSynchCorePRPQueue iterator, and response of asynchronous evaluations which duplicate queued beforeSynchCorePRPQueue evaluations | |
| PRPQueue | beforeSynchCorePRPQueue |
| used to bookkeep vars/set/response of nonduplicate asynchronous core evaluations. This is the queue of jobs populated by asynchronous map() that is later scheduled in synchronize() or synchronize_nowait(). | |
| PRPQueue | beforeSynchAlgPRPQueue |
| used to bookkeep vars/set/response of asynchronous algebraic evaluations. This is the queue of algebraic jobs populated by asynchronous map() that is later evaluated in synchronize() or synchronize_nowait(). | |
| PRPQueue | asynchLocalActivePRPQueue |
| used by nonblocking asynchronous local schedulers to bookkeep active local jobs | |
| std::map< int, IntSizetPair > | msgPassRunningMap |
| used by nonblocking message passing schedulers to bookkeep which jobs are running remotely | |
| int | nowaitEvalIdRef |
| fnEvalId reference point for preserving modulo arithmetic-based job assignment in case of peer static nonblocking schedulers | |
| MPIPackBuffer * | sendBuffers |
| array of pack buffers for evaluation jobs queued to a server | |
| MPIUnpackBuffer * | recvBuffers |
| array of unpack buffers for evaluation jobs returned by a server | |
| MPI_Request * | recvRequests |
| array of requests for nonblocking evaluation receives | |
Derived class within the interface class hierarchy for supporting interfaces to simulation codes.
ApplicationInterface provides an interface class for performing parameter to response mappings using simulation code(s). It provides common functionality for a number of derived classes and contains the majority of all of the scheduling algorithms in DAKOTA. The derived classes provide the specifics for managing code invocations using system calls, forks, direct procedure calls, or distributed resource facilities.
|
inlineprotectedvirtual |
DataInterface.cpp defaults of 0 servers are needed to distinguish an explicit user request for 1 server (serialization of a parallelism level) from no user request (use parallel auto-config). This default causes problems when init_communicators() is not called for an interface object (e.g., static scheduling fails in DirectApplicInterface::derived_map() for NestedModel::optionalInterface). This is the reason for this function: to reset certain defaults for interface objects that are used serially.
Reimplemented from Interface.
References ApplicationInterface::init_serial_analyses(), and ApplicationInterface::init_serial_evaluations().
|
protectedvirtual |
Provides a "mapping" of variables to responses using a simulation. Protected due to Interface letter-envelope idiom.
The function evaluator for application interfaces. Called from derived_evaluate() and derived_evaluate_nowait() in derived Model classes. If asynch_flag is not set, perform a blocking evaluation (using derived_map()). If asynch_flag is set, add the job to the beforeSynchCorePRPQueue queue for execution by one of the scheduler routines in synchronize() or synchronize_nowait(). Duplicate function evaluations are detected with duplication_detect().
Reimplemented from Interface.
References Response::active_set(), Interface::algebraic_mappings(), Interface::algebraicMappings, Interface::asv_mapping(), ApplicationInterface::asvControlFlag, ApplicationInterface::batchEval, ApplicationInterface::beforeSynchAlgPRPQueue, ApplicationInterface::beforeSynchCorePRPQueue, ApplicationInterface::broadcast_evaluation(), Response::copy(), Interface::coreMappings, Interface::currEvalId, Dakota::data_pairs, ApplicationInterface::defaultASV, ApplicationInterface::derived_map(), ApplicationInterface::duplication_detect(), ApplicationInterface::evalCacheFlag, Interface::evalIdCntr, Interface::fineGrainEvalCounters, Interface::fnGradCounter, Interface::fnHessCounter, Interface::fnLabels, Interface::fnValCounter, Response::function_labels(), Interface::init_algebraic_mappings(), ApplicationInterface::init_default_asv(), Interface::init_evaluation_counters(), Interface::interfaceId, ApplicationInterface::manage_failure(), Interface::multiProcEvalFlag, Interface::newEvalIdCntr, Interface::newFnGradCounter, Interface::newFnHessCounter, Interface::newFnValCounter, Interface::outputLevel, ApplicationInterface::parallelLib, ActiveSet::request_vector(), Interface::response_mapping(), ApplicationInterface::restartFileFlag, ApplicationInterface::sharedRespData, and ParallelLibrary::write_restart().
|
protectedvirtual |
executes a blocking schedule for asynchronous evaluations in the beforeSynchCorePRPQueue and returns all jobs
This function provides blocking synchronization for all cases of asynchronous evaluations, including the local asynchronous case (background system call, nonblocking fork, & multithreads), the message passing case, and the hybrid case. Called from derived_synchronize() in derived Model classes.
Reimplemented from Interface.
References Interface::algebraic_mappings(), Interface::algebraicMappings, Interface::asv_mapping(), ApplicationInterface::asynchLocalEvalStatic, ApplicationInterface::asynchronous_local_evaluations(), ApplicationInterface::beforeSynchAlgPRPQueue, ApplicationInterface::beforeSynchCorePRPQueue, ApplicationInterface::beforeSynchDuplicateMap, Interface::cachedResponseMap, Interface::coreMappings, ApplicationInterface::evalScheduling, ApplicationInterface::historyDuplicateMap, Interface::ieDedMasterFlag, ApplicationInterface::ieMessagePass, Interface::interfaceId, Interface::interfaceType, ApplicationInterface::master_dynamic_schedule_evaluations(), Interface::multiProcEvalFlag, Interface::outputLevel, ApplicationInterface::peer_dynamic_schedule_evaluations(), ApplicationInterface::peer_static_schedule_evaluations(), Interface::rawResponseMap, Interface::response_mapping(), and ApplicationInterface::sharedRespData.
|
protectedvirtual |
executes a nonblocking schedule for asynchronous evaluations in the beforeSynchCorePRPQueue and returns a partial set of completed jobs
This function provides nonblocking synchronization for the local asynchronous case and selected nonblocking message passing schedulers. Called from derived_synchronize_nowait() in derived Model classes.
Reimplemented from Interface.
References Interface::algebraic_mappings(), Interface::algebraicMappings, Interface::asv_mapping(), ApplicationInterface::asynchLocalEvalStatic, ApplicationInterface::asynchronous_local_evaluations_nowait(), ApplicationInterface::beforeSynchAlgPRPQueue, ApplicationInterface::beforeSynchCorePRPQueue, ApplicationInterface::beforeSynchDuplicateMap, Interface::cachedResponseMap, Interface::coreMappings, ParamResponsePair::eval_id(), ApplicationInterface::evalScheduling, ApplicationInterface::headerFlag, ApplicationInterface::historyDuplicateMap, Interface::ieDedMasterFlag, ApplicationInterface::ieMessagePass, Interface::interfaceId, Interface::interfaceType, Dakota::lookup_by_eval_id(), ApplicationInterface::master_dynamic_schedule_evaluations_nowait(), Interface::multiProcEvalFlag, Interface::outputLevel, ApplicationInterface::peer_dynamic_schedule_evaluations_nowait(), ApplicationInterface::peer_static_schedule_evaluations_nowait(), Interface::rawResponseMap, ParamResponsePair::response(), Interface::response_mapping(), ApplicationInterface::sharedRespData, and Response::update().
|
protectedvirtual |
run on evaluation servers to serve the iterator master
Invoked by the serve() function in derived Model classes. Passes control to serve_evaluations_synch(), serve_evaluations_asynch(), serve_evaluations_synch_peer(), or serve_evaluations_asynch_peer() according to specified concurrency, partition, and scheduler configuration.
Reimplemented from Interface.
References ApplicationInterface::asynchLocalEvalConcurrency, ApplicationInterface::evalServerId, Interface::ieDedMasterFlag, ApplicationInterface::serve_evaluations_asynch(), ApplicationInterface::serve_evaluations_asynch_peer(), ApplicationInterface::serve_evaluations_synch(), and ApplicationInterface::serve_evaluations_synch_peer().
|
protectedvirtual |
used by the iterator master to terminate evaluation servers
This code is executed on the iteratorComm rank 0 processor when iteration on a particular model is complete. It sends a termination signal (tag = 0 instead of a valid fn_eval_id) to each of the slave analysis servers. NOTE: This function is called from the Strategy layer even when in serial mode. Therefore, use iteratorCommSize to provide appropriate fall through behavior.
Reimplemented from Interface.
References ParallelLibrary::bcast_e(), ParallelLibrary::free(), ParallelConfiguration::ie_parallel_level(), Interface::ieDedMasterFlag, ParallelLibrary::isend_ie(), ApplicationInterface::iteratorCommSize, Interface::multiProcEvalFlag, ApplicationInterface::numEvalServers, Interface::outputLevel, ParallelLibrary::parallel_configuration(), and ApplicationInterface::parallelLib.
|
protectedvirtual |
perform construct-time error checks on the parallel configuration
Override DirectApplicInterface definition if plug-in to allow batch processing in Plugin{Serial,Parallel}DirectApplicInterface.cpp
Reimplemented in SysCallApplicInterface, Pybind11Interface, ProcessHandleApplicInterface, and DirectApplicInterface.
Referenced by ApplicationInterface::init_communicators().
|
protectedvirtual |
perform run-time error checks on the parallel configuration
Override DirectApplicInterface definition if plug-in to allow batch processing in Plugin{Serial,Parallel}DirectApplicInterface.cpp
Reimplemented in SysCallApplicInterface, SoleilDirectApplicInterface, Pybind11Interface, ProcessHandleApplicInterface, SerialDirectApplicInterface, ParallelDirectApplicInterface, and DirectApplicInterface.
Referenced by ApplicationInterface::set_communicators().
|
protected |
blocking dynamic schedule of all analyses within a function evaluation using message passing
This code is called from derived classes to provide the master portion of a master-slave algorithm for the dynamic scheduling of analyses among slave servers. It is patterned after master_dynamic_schedule_evaluations(). It performs no analyses locally and matches either serve_analyses_synch() or serve_analyses_asynch() on the slave servers, depending on the value of asynchLocalAnalysisConcurrency. Dynamic scheduling assigns jobs in 2 passes. The 1st pass gives each server the same number of jobs (equal to asynchLocalAnalysisConcurrency). The 2nd pass assigns the remaining jobs to slave servers as previous jobs are completed. Single- and multilevel parallel use intra- and inter-communicators, respectively, for send/receive. Specific syntax is encapsulated within ParallelLibrary.
References ApplicationInterface::asynchLocalAnalysisConcurrency, ParallelLibrary::free(), ParallelLibrary::irecv_ea(), ParallelLibrary::isend_ea(), ApplicationInterface::numAnalysisDrivers, ApplicationInterface::numAnalysisServers, ApplicationInterface::parallelLib, ParallelLibrary::waitall(), and ParallelLibrary::waitsome().
Referenced by ProcessHandleApplicInterface::create_evaluation_process(), SysCallApplicInterface::create_evaluation_process(), and DirectApplicInterface::derived_map().
|
protected |
serve the master analysis scheduler and manage one synchronous analysis job at a time
This code is called from derived classes to run synchronous analyses on slave processors. The slaves receive requests (blocking receive), do local derived_map_ac's, and return codes. This is done continuously until a termination signal is received from the master. It is patterned after serve_evaluations_synch().
References ApplicationInterface::analysisCommRank, ParallelLibrary::bcast_a(), ParallelLibrary::isend_ea(), ApplicationInterface::multiProcAnalysisFlag, ApplicationInterface::parallelLib, ParallelLibrary::recv_ea(), ApplicationInterface::synchronous_local_analysis(), and ParallelLibrary::wait().
Referenced by ProcessHandleApplicInterface::create_evaluation_process(), SysCallApplicInterface::create_evaluation_process(), and DirectApplicInterface::derived_map().
checks data_pairs and beforeSynchCorePRPQueue to see if the current evaluation request has already been performed or queued
Called from map() to check incoming evaluation request for duplication with content of data_pairs and beforeSynchCorePRPQueue.
If duplication is detected, return true, else return false. Manage bookkeeping with historyDuplicateMap and beforeSynchDuplicateMap. Note that the list searches can get very expensive if a long list is searched on every new function evaluation (either from a large number of previous jobs, a large number of pending jobs, or both). For this reason, a user request for deactivation of the evaluation cache results in a complete bypass of duplication_detect(), even though a beforeSynchCorePRPQueue search would still be meaningful. Since the intent of this request is to streamline operations, both list searches are bypassed.
References Response::active_set(), ApplicationInterface::beforeSynchCorePRPQueue, ApplicationInterface::beforeSynchDuplicateMap, Response::copy(), Dakota::data_pairs, ParamResponsePair::eval_id(), Interface::evalIdCntr, ApplicationInterface::historyDuplicateMap, Interface::interfaceId, Dakota::lookup_by_val(), ApplicationInterface::nearbyDuplicateDetect, ApplicationInterface::nearbyTolerance, and Response::update().
Referenced by ApplicationInterface::map().
|
private |
initialize default ASV if needed; this is done at run time due to post-construct time Response size changes.
If the user has specified active_set_vector as off, then map() uses a default ASV which is constant for all function evaluations (so that the user need not check the content of the ASV on each evaluation). Only initialized if needed and not already sized.
References ApplicationInterface::asvControlFlag, ApplicationInterface::defaultASV, ApplicationInterface::gradientType, ApplicationInterface::gradMixedAnalyticIds, ApplicationInterface::hessianType, and ApplicationInterface::hessMixedAnalyticIds.
Referenced by ApplicationInterface::map().
|
private |
blocking dynamic schedule of all evaluations in beforeSynchCorePRPQueue using message passing on a dedicated master partition; executes on iteratorComm master
This code is called from synchronize() to provide the master portion of a master-slave algorithm for the dynamic scheduling of evaluations among slave servers. It performs no evaluations locally and matches either serve_evaluations_synch() or serve_evaluations_asynch() on the slave servers, depending on the value of asynchLocalEvalConcurrency. Dynamic scheduling assigns jobs in 2 passes. The 1st pass gives each server the same number of jobs (equal to asynchLocalEvalConcurrency). The 2nd pass assigns the remaining jobs to slave servers as previous jobs are completed and returned. Single- and multilevel parallel use intra- and inter-communicators, respectively, for send/receive. Specific syntax is encapsulated within ParallelLibrary.
peer
References ApplicationInterface::asynchLocalEvalConcurrency, ApplicationInterface::beforeSynchCorePRPQueue, Dakota::lookup_by_eval_id(), ApplicationInterface::numEvalServers, Interface::outputLevel, ApplicationInterface::parallelLib, ApplicationInterface::receive_evaluation(), ApplicationInterface::recvBuffers, ApplicationInterface::recvRequests, ApplicationInterface::send_evaluation(), ApplicationInterface::sendBuffers, ParallelLibrary::waitall(), and ParallelLibrary::waitsome().
Referenced by ApplicationInterface::synchronize().
|
private |
blocking static schedule of all evaluations in beforeSynchCorePRPQueue using message passing on a peer partition; executes on iteratorComm master
This code runs on the iteratorCommRank 0 processor (the iterator) and is called from synchronize() in order to manage a static schedule for cases where peer 1 must block when evaluating its local job allocation (e.g., single or multiprocessor direct interface evaluations). It matches serve_evaluations_peer() for any other processors within the first evaluation partition and serve_evaluations_{synch,asynch}() for all other evaluation partitions (depending on asynchLocalEvalConcurrency). It performs function evaluations locally for its portion of the job allocation using either asynchronous_local_evaluations() or synchronous_local_evaluations(). Single-level and multilevel parallel use intra- and inter-communicators, respectively, for send/receive. Specific syntax is encapsulated within ParallelLibrary. The iteratorCommRank 0 processor assigns the static schedule since it is the only processor with access to beforeSynchCorePRPQueue (it runs the iterator and calls synchronize). The alternate design of each peer selecting its own jobs using the modulus operator would be applicable if execution of this function (and therefore the job list) were distributed.
References ApplicationInterface::asynchLocalEvalConcurrency, ApplicationInterface::asynchronous_local_evaluations(), ApplicationInterface::beforeSynchCorePRPQueue, ApplicationInterface::numEvalServers, Interface::outputLevel, ApplicationInterface::parallelLib, ApplicationInterface::receive_evaluation(), ApplicationInterface::recvBuffers, ApplicationInterface::recvRequests, ApplicationInterface::send_evaluation(), ApplicationInterface::sendBuffers, ApplicationInterface::synchronous_local_evaluations(), and ParallelLibrary::waitall().
Referenced by ApplicationInterface::synchronize().
|
private |
blocking dynamic schedule of all evaluations in beforeSynchCorePRPQueue using message passing on a peer partition; executes on iteratorComm master
This code runs on the iteratorCommRank 0 processor (the iterator) and is called from synchronize() in order to manage a dynamic schedule, as enabled by nonblocking management of local asynchronous jobs. It matches serve_evaluations_{synch,asynch}() for other evaluation partitions, depending on asynchLocalEvalConcurrency; it does not match serve_evaluations_peer() since, for local asynchronous jobs, the first evaluation partition cannot be multiprocessor. It performs function evaluations locally for its portion of the job allocation using asynchronous_local_evaluations_nowait(). Single-level and multilevel parallel use intra- and inter-communicators, respectively, for send/receive. Specific syntax is encapsulated within ParallelLibrary.
References ApplicationInterface::assign_asynch_local_queue(), ApplicationInterface::asynchLocalEvalConcurrency, ApplicationInterface::beforeSynchCorePRPQueue, ApplicationInterface::msgPassRunningMap, ApplicationInterface::numEvalServers, Interface::outputLevel, ApplicationInterface::recvBuffers, ApplicationInterface::recvRequests, ApplicationInterface::send_evaluation(), ApplicationInterface::sendBuffers, ApplicationInterface::test_local_backfill(), and ApplicationInterface::test_receives_backfill().
Referenced by ApplicationInterface::synchronize().
|
private |
perform all jobs in prp_queue using asynchronous approaches on the local processor
This function provides blocking synchronization for the local asynch case (background system call, nonblocking fork, or threads). It can be called from synchronize() for a complete local scheduling of all asynchronous jobs or from peer_{static,dynamic}_schedule_evaluations() to perform a local portion of the total job set. It uses derived_map_asynch() to initiate asynchronous evaluations and wait_local_evaluations() to capture completed jobs, and mirrors the master_dynamic_schedule_evaluations() message passing scheduler as much as possible (wait_local_evaluations() is modeled after MPI_Waitsome()).
References ApplicationInterface::assign_asynch_local_queue(), ApplicationInterface::asynchLocalActivePRPQueue, ApplicationInterface::asynchLocalEvalConcurrency, ApplicationInterface::asynchLocalEvalStatic, ApplicationInterface::batchEval, ApplicationInterface::completionSet, ApplicationInterface::launch_asynch_local(), ApplicationInterface::localServerAssigned, Dakota::lookup_by_eval_id(), ApplicationInterface::numEvalServers, Interface::outputLevel, ApplicationInterface::process_asynch_local(), Interface::rawResponseMap, and ApplicationInterface::wait_local_evaluations().
Referenced by ApplicationInterface::peer_static_schedule_evaluations(), and ApplicationInterface::synchronize().
|
private |
perform all jobs in prp_queue using synchronous approaches on the local processor
This function provides blocking synchronization for the local synchronous case (foreground system call, blocking fork, or procedure call from derived_map()). It is called from peer_static_schedule_evaluations() to perform a local portion of the total job set.
References ApplicationInterface::broadcast_evaluation(), Interface::currEvalId, ApplicationInterface::derived_map(), ApplicationInterface::manage_failure(), Interface::multiProcEvalFlag, and ApplicationInterface::process_synch_local().
Referenced by ApplicationInterface::peer_static_schedule_evaluations(), and ApplicationInterface::peer_static_schedule_evaluations_nowait().
|
private |
execute a nonblocking dynamic schedule in a master-slave partition
This code is called from synchronize_nowait() to provide the master portion of a nonblocking master-slave algorithm for the dynamic scheduling of evaluations among slave servers. It performs no evaluations locally and matches either serve_evaluations_synch() or serve_evaluations_asynch() on the slave servers, depending on the value of asynchLocalEvalConcurrency. Dynamic scheduling assigns jobs in 2 passes. The 1st pass gives each server the same number of jobs (equal to asynchLocalEvalConcurrency). The 2nd pass assigns the remaining jobs to slave servers as previous jobs are completed. Single- and multilevel parallel use intra- and inter-communicators, respectively, for send/receive. Specific syntax is encapsulated within ParallelLibrary.
References Dakota::abort_handler(), ApplicationInterface::asynchLocalEvalConcurrency, ApplicationInterface::beforeSynchCorePRPQueue, ApplicationInterface::headerFlag, ApplicationInterface::msgPassRunningMap, ApplicationInterface::numEvalServers, ApplicationInterface::recvBuffers, ApplicationInterface::recvRequests, ApplicationInterface::send_evaluation(), ApplicationInterface::sendBuffers, and ApplicationInterface::test_receives_backfill().
Referenced by ApplicationInterface::synchronize_nowait().
|
private |
execute a nonblocking static schedule in a peer partition
This code runs on the iteratorCommRank 0 processor (the iterator) and is called from synchronize_nowait() in order to manage a nonblocking static schedule. It matches serve_evaluations_synch() for other evaluation partitions (asynchLocalEvalConcurrency == 1). It performs blocking local function evaluations, one at a time, for its portion of the static schedule and checks for remote completions in between each local completion. Therefore, unlike peer_dynamic_schedule_evaluations_nowait(), this scheduler will always return at least one job. Single-level and multilevel parallel use intra- and inter-communicators, respectively, for send/receive, with specific syntax as encapsulated within ParallelLibrary. The iteratorCommRank 0 processor assigns the static schedule since it is the only processor with access to beforeSynchCorePRPQueue (it runs the iterator and calls synchronize). The alternate design of each peer selecting its own jobs using the modulus operator would be applicable if execution of this function (and therefore the job list) were distributed.
References Dakota::abort_handler(), ApplicationInterface::assign_asynch_local_queue(), ApplicationInterface::assign_asynch_local_queue_nowait(), ApplicationInterface::asynchLocalActivePRPQueue, ApplicationInterface::asynchLocalEvalConcurrency, ApplicationInterface::beforeSynchCorePRPQueue, ApplicationInterface::headerFlag, Interface::interfaceType, Dakota::lookup_by_eval_id(), ApplicationInterface::msgPassRunningMap, Interface::multiProcEvalFlag, ApplicationInterface::nowaitEvalIdRef, ApplicationInterface::numEvalServers, ApplicationInterface::recvBuffers, ApplicationInterface::recvRequests, ApplicationInterface::send_evaluation(), ApplicationInterface::sendBuffers, ApplicationInterface::synchronous_local_evaluations(), ApplicationInterface::test_local_backfill(), and ApplicationInterface::test_receives_backfill().
Referenced by ApplicationInterface::synchronize_nowait().
|
private |
execute a nonblocking dynamic schedule in a peer partition
This code runs on the iteratorCommRank 0 processor (the iterator) and is called from synchronize_nowait() in order to manage a nonblocking static schedule. It matches serve_evaluations_{synch,asynch}() for other evaluation partitions (depending on asynchLocalEvalConcurrency). It performs nonblocking local function evaluations for its portion of the static schedule using asynchronous_local_evaluations(). Single-level and multilevel parallel use intra- and inter-communicators, respectively, for send/receive, with specific syntax as encapsulated within ParallelLibrary. The iteratorCommRank 0 processor assigns the dynamic schedule since it is the only processor with access to beforeSynchCorePRPQueue (it runs the iterator and calls synchronize). The alternate design of each peer selecting its own jobs using the modulus operator would be applicable if execution of this function (and therefore the job list) were distributed.
References Dakota::abort_handler(), ApplicationInterface::assign_asynch_local_queue(), ApplicationInterface::assign_asynch_local_queue_nowait(), ApplicationInterface::asynchLocalActivePRPQueue, ApplicationInterface::asynchLocalEvalConcurrency, ApplicationInterface::beforeSynchCorePRPQueue, ApplicationInterface::headerFlag, Dakota::lookup_by_eval_id(), ApplicationInterface::msgPassRunningMap, ApplicationInterface::numEvalServers, ApplicationInterface::recvBuffers, ApplicationInterface::recvRequests, ApplicationInterface::send_evaluation(), ApplicationInterface::sendBuffers, ApplicationInterface::test_local_backfill(), and ApplicationInterface::test_receives_backfill().
Referenced by ApplicationInterface::synchronize_nowait().
|
private |
launch new jobs in prp_queue asynchronously (if capacity is available), perform nonblocking query of all running jobs, and process any completed jobs (handles both local master- and local peer-scheduling cases)
This function provides nonblocking synchronization for the local asynch case (background system call, nonblocking fork, or threads). It is called from synchronize_nowait() and passed the complete set of all asynchronous jobs (beforeSynchCorePRPQueue). It uses derived_map_asynch() to initiate asynchronous evaluations and test_local_evaluations() to capture completed jobs in nonblocking mode. It mirrors a nonblocking message passing scheduler as much as possible (test_local_evaluations() modeled after MPI_Testsome()). The result of this function is rawResponseMap, which uses eval_id as a key. It is assumed that the incoming local_prp_queue contains only active and new jobs - i.e., all completed jobs are cleared by synchronize_nowait().
Also supports asynchronous local evaluations with static scheduling. This scheduling policy specifically ensures that a completed asynchronous evaluation eval_id is replaced with an equivalent one, modulo asynchLocalEvalConcurrency. In the nowait case, this could render some servers idle if evaluations don't come in eval_id order or some evaluations are cancelled by the caller in between calls. If this function is called with unlimited local eval concurrency, the static scheduling request is ignored.
References ApplicationInterface::assign_asynch_local_queue_nowait(), ApplicationInterface::asynchLocalActivePRPQueue, ApplicationInterface::asynchLocalEvalConcurrency, ApplicationInterface::asynchLocalEvalStatic, ApplicationInterface::headerFlag, and ApplicationInterface::test_local_backfill().
Referenced by ApplicationInterface::synchronize_nowait().
|
private |
serve the evaluation message passing schedulers and perform one synchronous evaluation at a time
This code is invoked by serve_evaluations() to perform one synchronous job at a time on each slave/peer server. The servers receive requests (blocking receive), do local synchronous maps, and return results. This is done continuously until a termination signal is received from the master (sent via stop_evaluation_servers()).
References ParallelLibrary::bcast_e(), Interface::currEvalId, ApplicationInterface::derived_map(), ApplicationInterface::evalCommRank, ParallelLibrary::isend_ie(), ApplicationInterface::lenResponseMessage, ApplicationInterface::lenVarsActSetMessage, ApplicationInterface::manage_failure(), Interface::multiProcEvalFlag, ApplicationInterface::parallelLib, ParallelLibrary::recv_ie(), MPIPackBuffer::reset(), ApplicationInterface::sharedRespData, and ParallelLibrary::wait().
Referenced by ApplicationInterface::serve_evaluations().
|
private |
serve the evaluation message passing schedulers and perform one synchronous evaluation at a time as part of the 1st peer
This code is invoked by serve_evaluations() to perform a synchronous evaluation in coordination with the iteratorCommRank 0 processor (the iterator) for static schedules. The bcast() matches either the bcast() in synchronous_local_evaluations(), which is invoked by peer_static_schedule_evaluations(), or the bcast() in map().
References ParallelLibrary::bcast_e(), Interface::currEvalId, ApplicationInterface::derived_map(), ApplicationInterface::lenVarsActSetMessage, ApplicationInterface::manage_failure(), ApplicationInterface::parallelLib, and ApplicationInterface::sharedRespData.
Referenced by ApplicationInterface::serve_evaluations().
|
private |
serve the evaluation message passing schedulers and manage multiple asynchronous evaluations
This code is invoked by serve_evaluations() to perform multiple asynchronous jobs on each slave/peer server. The servers test for any incoming jobs, launch any new jobs, process any completed jobs, and return any results. Each of these components is nonblocking, although the server loop continues until a termination signal is received from the master (sent via stop_evaluation_servers()). In the master-slave case, the master maintains the correct number of jobs on each slave. In the static scheduling case, each server is responsible for limiting concurrency (since the entire static schedule is sent to the peers at start up).
References Dakota::abort_handler(), ApplicationInterface::asynchLocalActivePRPQueue, ApplicationInterface::asynchLocalEvalConcurrency, ParallelLibrary::bcast_e(), ApplicationInterface::completionSet, ApplicationInterface::evalCommRank, ParallelLibrary::irecv_ie(), ApplicationInterface::launch_asynch_local(), ApplicationInterface::lenResponseMessage, ApplicationInterface::lenVarsActSetMessage, Dakota::lookup_by_eval_id(), Interface::multiProcEvalFlag, ApplicationInterface::parallelLib, ParallelLibrary::recv_ie(), ParallelLibrary::send_ie(), ParallelLibrary::test(), and ApplicationInterface::test_local_evaluations().
Referenced by ApplicationInterface::serve_evaluations().
|
private |
serve the evaluation message passing schedulers and perform multiple asynchronous evaluations as part of the 1st peer
This code is invoked by serve_evaluations() to perform multiple asynchronous jobs on multiprocessor slave/peer servers. It matches the multiProcEvalFlag bcasts in ApplicationInterface::asynchronous_local_evaluations().
References Dakota::abort_handler(), ApplicationInterface::asynchLocalActivePRPQueue, ApplicationInterface::asynchLocalEvalConcurrency, ParallelLibrary::bcast_e(), ApplicationInterface::completionSet, ApplicationInterface::launch_asynch_local(), ApplicationInterface::lenVarsActSetMessage, Dakota::lookup_by_eval_id(), ApplicationInterface::parallelLib, and ApplicationInterface::test_local_evaluations().
Referenced by ApplicationInterface::serve_evaluations().